RDB:冗長化・フェイルオーバー
DBサーバーの冗長化と障害時のフェイルオーバーをサポートしています。
冗長化のタイプは、データ優先 のみ選択できます。
また、RDBを構成する仮想基盤では、シングル構成・冗長構成に関わらず、自動フェイルオーバー(HA機能)を採用しています。
自動フェイルオーバー(HA機能)については、 サービスレベル目標(SLO)について の「自動フェイルオーバー」をご参照ください。
「データ優先」の特徴
| 冗長化タイプ | データ優先 |
|---|---|
| 主な特長 | ・ データ同期 ・ データの冗長性を確保する ※1 |
| 待機系へのアクセス | アクセス不可 |
| 待機系の場所 | 同一ゾーン内 |
| 主系への昇格 | 主系障害時に自動で待機系にフェイルオーバーし主系昇格 |
| 切り替え時間 ※2 | 1分程度 |
| 待機系の数 | 1 |
| 対応データベース | MySQL、PostgreSQL |
※1「データ優先」でも、待機系とは別にリードレプリカを作成可能です。ただし、主系からのフェイルオーバー先としては利用できません。
※2 切り替え時間はデータベースの利用のされ方などにより変動します。
冗長化
- 冗長化機能(データ優先)をオンにすると、自動で別の物理ホストに待機系のDBサーバーが作成されます。
主系から待機系へと同期的にデータが複製されるので、データの冗長性を確保できます。 - 冗長化機能(データ優先)がオンの場合は、バックアップ処理(手動によるDBスナップショット・自動バックアップ) は待機系からバックアップの取得が実施されます。
本動作により、バックアップ処理中に発生するIO性能の低下を軽減されます。 - 冗長化機能(データ優先)は、以下操作の時点で有効にできます。
- DBサーバーを作成する。
- DBサーバーの設定変更を行い、途中から冗長化機能(データ優先)を有効にする。
注意事項
- 冗長化機能(データ優先)は、2つのDBサービスが並行して起動している類のものではありません。
複製されているのはブロックデバイス単位のデータです。 - 冗長化機能(データ優先)は、読み出し専用のDBサーバーでスケールアウトを行う用途には利用できません。また、待機系から読み出し処理はできません。
読み出し専用のDBサーバーを用意したい場合には、リードレプリカを利用してください。 - 同期的なデータの複製が行われるため、冗長化機能オフの場合に比べ、冗長化機能(データ優先)オンの場合にはレイテンシーが増大する可能性があります。
- DBサーバータイプとデータ量によって冗長化処理に時間がかかる場合があります。必要に応じてDBサーバータイプのスペックアップやデータ量の削減を実施してください。
冗長化機能は、ディスクレベルでの主系-待機系間の同期を行うため、フェイルオーバーのタイミングで主系に昇格したDBサーバーはメモリ上にDBデータのキャッシュ(MySQLの場合InnoDBのバッファプールなど、PostgreSQLの場合shared_buffers)を持っていません。お客様でキャッシュのウォームアップを行う必要があります。
フェイルオーバー
- 主系のDBサーバーが停止または利用不可になった場合には、フェイルオーバーが発動し、別物理ホストに存在する待機系のDBサーバーへの切り替えが行われます。
- 定期的なメンテナンスの際にもフェイルオーバーを行って片系ずつ設定を変更するため、DBサーバーの可用性を高めることができます。
- 単一の物理ホストに障害が起きても、フェイルオーバーにより継続してデータベースを利用可能です。
- フェイルオーバーの仕組みは、IPアドレスを持つ仮想のロードバランサーを利用して実現しています。
フェイルオーバーは自動で行われるため、データベースの利用を再開するまでに複雑な手順を踏む必要はありません。- フェイルオーバーが完了するまでにかかる時間の目安は1分程度ですが、主系のDBサーバーが利用不可になった時点のさまざまな条件に左右されます。
MySQL・PostgreSQLの場合、フェイルオーバーの完了に、クラッシュリカバリーの時間も考慮する必要があります。クラッシュリカバリーにはデータ量が多ければ多いほど時間がかかります。 - IPアドレスを持つ仮想のロードバランサーにて自動フェイルオーバー(HA機能)が発生した場合、自動フェイルオーバー(HA機能)の処理時間に加えてDBサービスの起動に最大2分程度の時間がかかります。
自動フェイルオーバー(HA機能)の詳細は、クラウド技術仕様/制限値(コンピューティング:クラウド サーバー(共有)タイプ)の自動フェイルオーバー(HA機能)を、自動フェイルオーバー(HA機能)にかかる時間は サービスレベル目標(SLO)について の「自動フェイルオーバー」を参照してください。
- フェイルオーバーが完了するまでにかかる時間の目安は1分程度ですが、主系のDBサーバーが利用不可になった時点のさまざまな条件に左右されます。
フェイルオーバーの発動条件
下記のいずれかの場合に主系から待機系へのフェイルオーバーが発生します。
- 物理ホストの障害
- 主系 DB サーバーの障害
- DBサーバータイプの変更
- DBサーバーの再起動時に強制フェイルオーバーを指定
動作詳細
フェイルオーバー発生時の動作
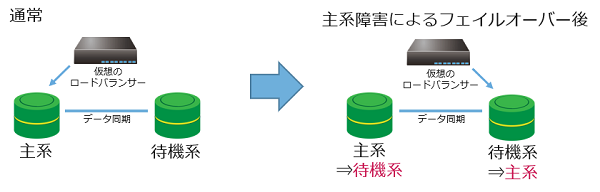
- 主系DBサーバーが待機系DBサーバーとして動作可能な場合
フェイルオーバーが発生した場合、自動で待機系DBサーバーが主系DBサーバーへ昇格します。
旧主系DBサーバーが待機系DBサーバーとして動作可能な場合、自動で主系DBサーバーが待機系DBサーバーへ降格し、主系DBサーバーと待機系DBサーバーが入れ換わった状態になります。
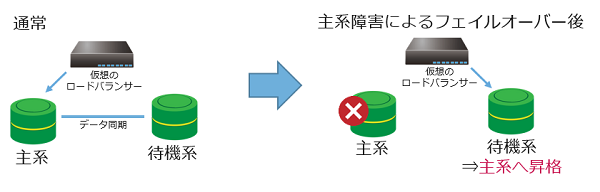
- 主系DBサーバーが待機系DBサーバーとして動作不可の場合
フェイルオーバーが発生した場合、自動で待機系DBサーバーが主系DBサーバーへ昇格します。
旧主系DBサーバーが待機系DBサーバーとして動作不可な場合、主系DBサーバーは切り離されます。
DBサーバーはシングル構成として引き続き利用できます。
- 主系DBサーバーが待機系DBサーバーとして動作可能な場合
再冗長化の方法
- 主系DBサーバーが待機系DBサーバーとして動作可能な場合
作業は必要ありません。引き続き冗長化したDBサーバーをご利用いただけます。 - 主系DBサーバーが待機系DBサーバーとして動作不可の場合
再度コントロールパネルより、冗長構成(データ優先)を設定することで、再冗長化されます。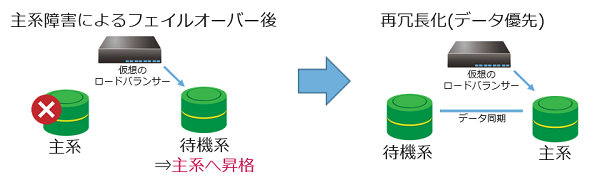
- 主系DBサーバーが待機系DBサーバーとして動作可能な場合
フィードバック
サービス利用中のトラブルは、サポート窓口にお願いします。
お役に立ちましたか?